3. 자료처리/빅데이터분석
Data Mining
SWExpert
2022. 7. 13. 21:33
I. 합리적 의사결정을 위한 가치정보 추출, Data Mining의 개요
가. Data Mining의 정의
- 대량의 데이터에 고급 통계 분석과 모델링 기법을 적용하여 데이터 간의 패턴과 관계를 도출, 의사결정에 활용할 수 있는 의미 있는 정보를 발견하는 과정
II. Data Mining 모델링 유형 및 Data Mining 적용 기술
가. Data Mining 모델링 유형
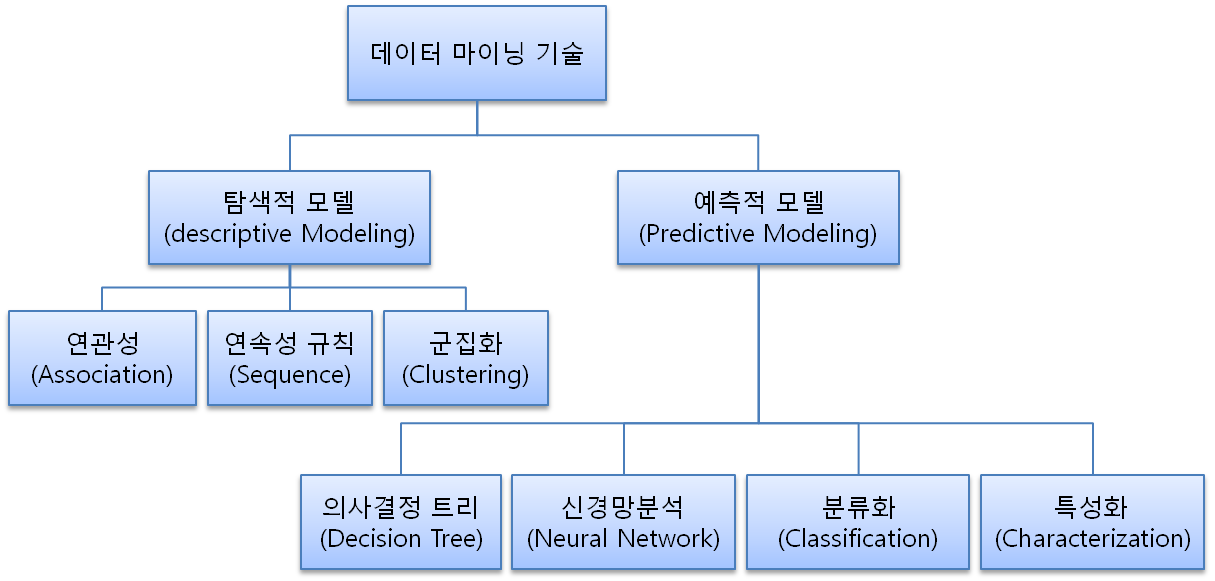
나 Data Mining 적용 기술
| 분류 | 기법 | 설명 |
| 탐색적 모델 | 연관성 규칙 | - 여러 개의 트랜잭션들 중에서 동시에 발생하는 트랜잭션의 연관 관계를 발견 [사례] - 넥타이를 구매하는 고객이 셔츠를 50%이상 구매하고, 정장과 벨트를 구매하는 고객은 코트를 구매할 확률이 40% 이상 - 교차판매, 묶음판매, 상품의 진열, 쿠폰 배부 등의 분야에서 활용  |
| 연속성 규칙 | - 개인별 트랜잭션 이력 데이터를 시계열적으로 분석하여 트랜잭션의 향후 발생 가능성을 예측하는 것 [사례] - A품목을 구입한 회원이 향후 H품목을 구입할 가능성은 75%이다. - 5번 회원에게 H품목을 추천하여 마케팅의 정확성을 높임  |
|
| 군집화 | - 상호간에 유사한 특성을 갖는 데이터들을 집단화 하는 과정 - 미리 정의한 특성에 대한 정보를 가지지 않는다는 점에서 ‘분류’와 차이 - K-means 알고리즘 [사례] - A~D의 데이터를 집단화하는 과정에서 고객 군집 별 특성을 파악함 - A 군집은 소득이 300만원 이상이고, 자녀가 2-3명이고 연령이 30대 군집 - B군집은 교육 수준이 높으며, 자녀는 모두 출가했고, 연평균 구매액이 200~300만원 정도  |
|
| 예측적 모델 | 의사결정트리 | 과거에 수집된 데이터들을 분석하여 이들 사이에 존재하는 패턴을 분류, 해당 분류의 값을 예측하는데 사용 |
| 신경망분석 | 뇌를 모방, 학습을 통한 예측(입력-은닉-출력) |
|
| 분류화 | - 이미 알려진 특정 그룹의 특징을 부여하고 정의된 분류에 맞게 구분 [사례] - 신용카드 신규 가입자를 낮음/중간/높음 신용 위험 집단으로 구분 - 경쟁자에게 이탈한 고객 |
|
| 특성화 | - 데이터 집합의 일반적인 특성을 분석하는 것으로 데이터의 요약 과정을 통하여 특성 규칙을 발견하는 것 |
III. 일반적인 Data Mining의 수행단계
가. Data Mining의 수행단계 개념도

나. Data Mining 상세 수행단계
| 수행단계 | 내용 |
| sampling/selecting | 방대한 양의 데이터로부터 모집단의 유형과 닮은 작은 양의 데이터 추출 |
| data cleaning, preprocessing | 데이터의 일관성을 위해 오류제거 작업을 통한 데이터 무결성 및 질 관리 |
| Transformation | 이미 알고 있는 사실들을 확인하여 수치화하는 작업을 시작으로 하여 보유하고 있는 수많은 변수들의 관계를 살펴보는 단계 |
| Modeling | 이전 단계에서 선정된 주요한 변수를 사용하여 다양한 모형을 접합해 보는 단계 |
| Reporting/ visualization | 사용자들에게 보기 편하고 이해하기 쉬운 형태로 제공 |